If you look at the recent data from Stack Exchange, the chart for StackOverflow isn't just a decline; it’s a terminal velocity nose-dive. Monthly question volume has cratered, and while some people are busy dancing on the grave of the "toxic moderator," they’re missing the much larger, much grimmer reality: we are losing the only high-signal, searchable archive of human engineering experience we ever had.
StackOverflow didn't die because of a few grumpy power users closing duplicate threads. It’s dying because we’ve traded a public library for a private, hallucinating butler.
The Fallacy of the "Toxic" Moderator
There is a popular narrative that StackOverflow’s strictness killed it. This is a comforting lie. The strictness was the point. The goal of the site was never to be a friendly chat room; it was to build a wiki of definitive answers. When a high-rep user closed your poorly phrased question about a NullPointerException in 2014, they weren't being a jerk—they were keeping the signal-to-noise ratio high enough that the site remained useful for the next decade.
Evidence shows that even the "friendly" branches of Stack Exchange, like the TeX community, are seeing the exact same collapse. The issue isn't manners; it’s the shift toward ephemeral, siloed platforms. We’ve moved our troubleshooting to Discord servers and Slack channels. When you solve a complex bug in a Discord thread, that knowledge is effectively dead to the rest of the world. It isn't indexed by search engines, and it won't help a developer facing the same problem three years from now. We are retreating into dark corners of the web, and the collective intelligence of the industry is shrinking because of it.
The LLM Dead End
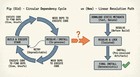
Then there’s the elephant in the room: Large Language Models. ChatGPT and Claude are fantastic at solving the "center-of-the-bell-curve" problems. They can write a boilerplate React component or explain a basic Python loop in seconds. But they are parasitic. They only know how to solve those problems because they were trained on the millions of human-verified answers on StackOverflow.

When we stop contributing to public repositories of knowledge because it’s "easier" to ask an LLM, we stop feeding the engine. LLMs are notoriously bad at the "edge of the map" problems—the weird, specific bugs that occur at the intersection of three different libraries and a specific OS kernel version. When you hit those, an LLM will confidently lie to you for three hours. In the old world, you’d find a 2016 StackOverflow thread where some developer in Germany spent three days debugging that exact issue and posted the one-line fix.
If the data creation stops, the models stagnate. We are currently living off the fumes of a decade of human collaboration, and we’re running out of gas.
The Death of the "Aha!" Moment
There is something deeply lonely about the new way we work. Writing a brilliant piece of code—like the user who published a novel method for calculating the distance to an ellipse—used to mean contributing to the "human knowledge base." You could see your solution cited in PhD papers or used in game engines. Now, that same genius might be fed into a model, stripped of its context, and regurgitated as an anonymous snippet without credit or the satisfaction of helping a peer.
We are moving toward a world where every developer works in a vacuum, assisted by an AI that can only tell them what has already been said a thousand times before. We’ve traded the "grumpy expert" who actually knew the answer for a "friendly idiot" who guesses. This isn't progress; it’s the dismantling of the digital commons.
StackOverflow was a miracle of collective effort that lasted fifteen years. We will realize how much we needed it only after the last expert logs off and we're left alone with the ghosts in the machine.