Large language models are built on a mountain of data, and much of that data comes from the open web—forums, code repositories, and community-driven sites. But the way AI companies scrape this information isn't just aggressive; it's exploitative. They're treating the internet as a free buffet, loading their plates with content created by volunteers and enthusiasts, then walking away without so much as a thank you. This isn't innovation; it's extraction.

The Server Siege: When Bots Become Bandits
If you've run a server recently, you've likely felt the weight of AI scrapers. These bots don't just visit; they assault. They ignore robots.txt, hammer endpoints with relentless requests, and force administrators to implement drastic measures—blocking entire regions, adding password protections, or deploying captchas. What was once an open resource becomes a fortress, all because companies like OpenAI and Meta decided that their training needs trump everyone else's bandwidth and goodwill. This isn't a minor inconvenience; it's a direct attack on the infrastructure that makes open collaboration possible.
Breaking the Social Contract
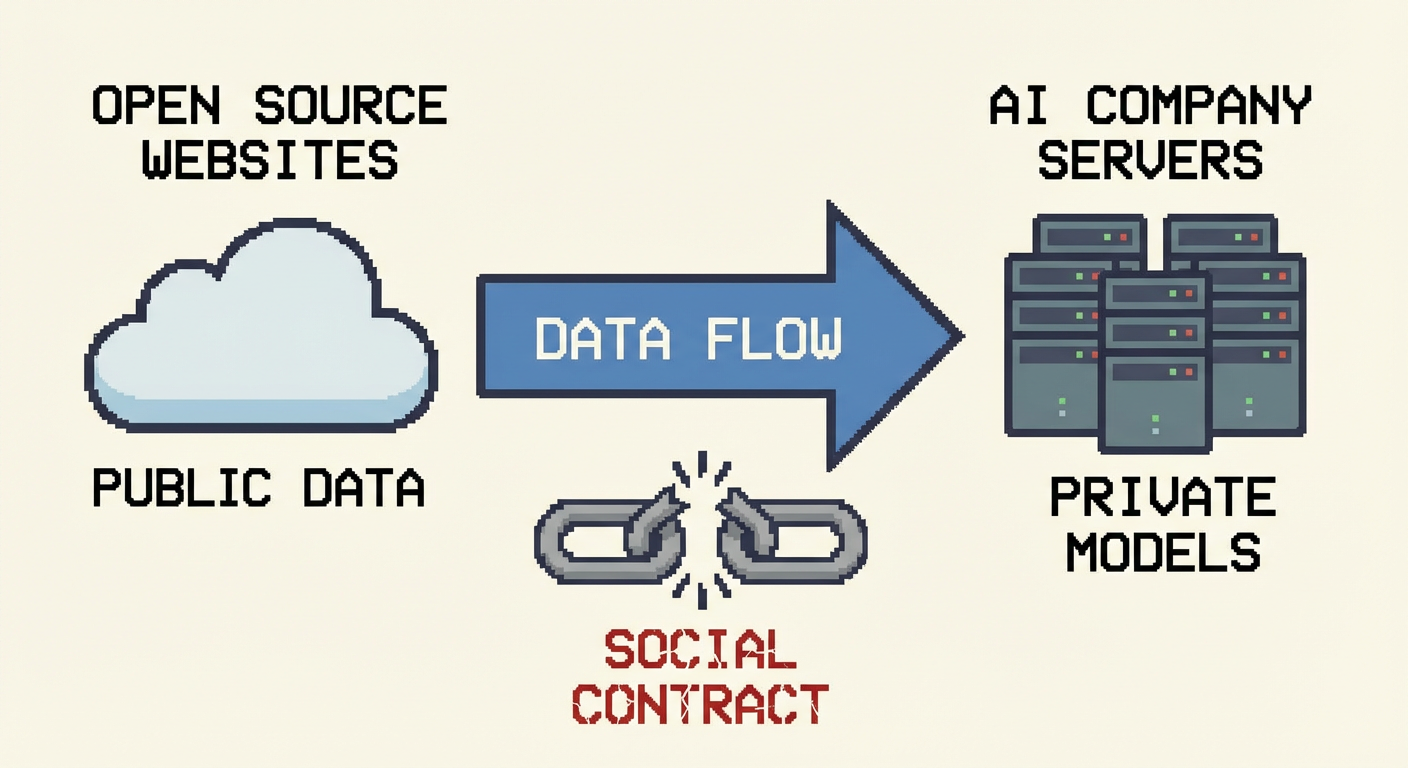
Open source operates on a simple principle: share freely, contribute back. When you use GPL-licensed code, you agree to share your modifications. When you benefit from community answers on sites like Stack Overflow, you're expected to give back when you can. AI scrapers shatter this contract. They take everything and give nothing in return, producing output that often competes with the very sources it drained. The decline in community contributions isn't a coincidence; it's a consequence. Why would anyone spend hours debugging code or writing documentation if their work is just fuel for a corporate black box?
Copyright Chaos and Corporate Hypocrisy
Copyright law is messy, but AI companies are exploiting its ambiguities with brazen hypocrisy. They hide behind "fair use" while scraping data that isn't publicly accessible or ignoring explicit terms. Meanwhile, these same companies would sue anyone who dared to replicate their models. Look at Adobe's history: they built a empire by cloning fonts, then used copyright to lock others out. AI firms are following the same playbook—grow big by taking, then lobby to change the rules so no one can take from them. It's corporatism dressed up as progress.
Fighting Back: From Tarpits to Legal Battles
Resistance is growing. Some site owners are adding cheeky footer text claiming ownership of AI IP, while others are deploying technical countermeasures—tarpitting scrapers, injecting prompt noise, or using blocklists. These tactics aren't just petty; they're necessary. But technical fixes alone won't solve the problem. We need legal and regulatory pressure. AI should be subject to the same rules as everyone else: if you use copyleft code, your derivatives must be open. If you scrape data, you must compensate or credit the sources. Consumer protection laws might even be invoked to prevent the mass harvesting of personal and creative work.
Conclusion: Time to Reclaim Our Digital Commons
AI has potential, but it cannot be built on theft. The current scraping frenzy is a betrayal of the open ethos that powered the internet's growth. It's time for developers, communities, and policymakers to demand accountability. Rate limits and WAF rules are stopgaps; real change requires holding AI companies to the same standards they enforce on others. If they want to use our work, they must pay their debt—not in vague promises, but in transparency, reciprocity, and respect. Otherwise, we risk letting a handful of corporations privatize the commons we all built.